
Apache Spark is a big data solution that has been proven to be easier & faster than Hadoop MapReduce. Spark is open-source software that the UC Berkeley RAD lab developed in 2009. Since being released to the public in 2010, Apache Spark has grown exceptionally and is used in many industries unprecedentedly.
Examining huge datasets is one of the most valuable technical skills. This tutorial will bring you one of the most used technologies, Apache Spark, combined with one of the most trending programming languages, i.e., Python, by learning about which you will be able to analyze massive datasets.
In the era of Big Data, developers need fast & reliable tools to process the streaming of data more than ever. Earlier, tools like MapReduce were most liked but were slow. To overcome this issue, Spark offers a solution that is both fast & general-purpose.
The main difference between MapReduce and Spark is that Spark runs computations in memory and later on the hard disk. Therefore, it allows high-speed access & data processing, reducing times from hours to minutes.
PySpark is a Python API for Spark, i.e., released by the Apache Spark community to support Python with Spark. Using PySpark, one can easily integrate programming & work with RDDs in Python programming language.
In addition, many features make it an excellent framework for working with huge datasets. Hence, many data engineers are switching to this tool.
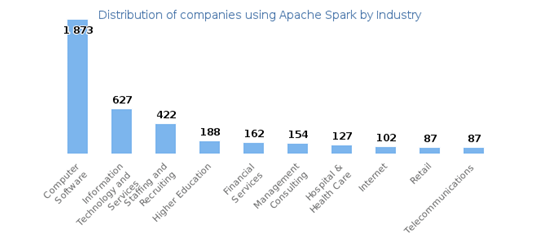
Apache Spark is one of the highest-using tools in different industries. Its use is not limited just to the IT industry, though it is maximum in IT. Even the big dogs of the IT industry are using Apache Spark for dealing with Big Data, e.g., Netflix, Oracle, Yahoo, Cisco, etc.
It is another sector where Apache Spark’s Real-Time processing plays an important role. Banks are using Spark to access & analyze their social media profiles to gain insights that can help in making the proper business decisions for credit risk assessment, targeted ads, & customer segmentation.
Spark can also reduce customer churn. Fraud Detection is one of the most widely used areas of Machine Learning where Spark is involved.
The retail & E-commerce industry can use Apache Spark with Python to gain insights and real-time transactions. Pyspark can also be used to improve recommendations to users based on new trends.
Yahoo is a big example of the media industry that uses Spark with Python. Yahoo uses Pyspark to design the new pages for the targeted audience by using ML features provided by Spark.
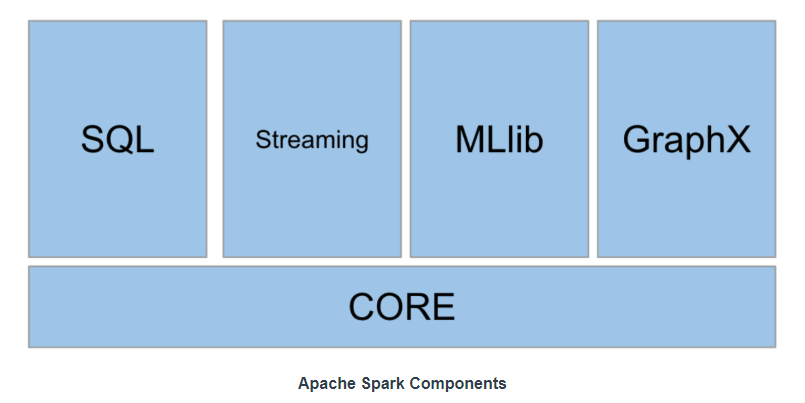
Spark Core is a general execution engine for the Spark platform that supports all other functionality of the spark platform. It contains the basic functionality of Spark. Also home to the API that defines RDDs, which is Spark’s central programming abstraction.
Package for working with structured data. It allows querying data via Apache hive as well as SQL. It supports various sources of data, like Parquet, Hive tables, JSON, CSV, etc.
Enables processing of live streams of data. Spark Streaming provides an API for manipulating the data streams that are similar to Spark Core’s RDD API.
MLlib is a scalable Machine learning library in Spark that examines high-quality algorithms and high speed. In addition, MLlib provides multiple machine learning algorithms, like regression, clustering, classification, etc.
GraphX is a library for manipulating graphs & performing graph-parallel computations. GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system. Moreover, it is a system where you can find PageRank & triangle counting algorithms.
Discover the most interesting topic
Get the latest articles delivered straight to your inbox and enjoy something new every week.
Explore All







