The most basic premise of the Window Function is to perform comparative analysis, which gives rise to its alternate name, i.e., Analytic Functions!
The functionality of Window Functions and GROUP BY Clause is quite similar. Both functions aggregate data, however, the former presents the aggregation against each row, while the latter collapses and summarizes it.
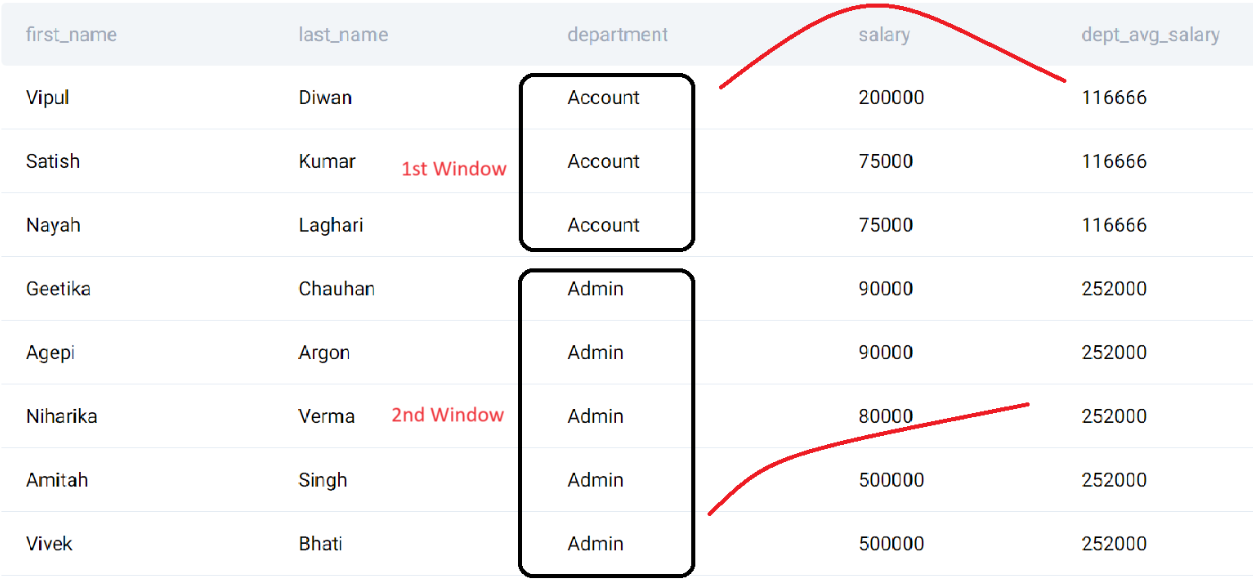
For the time being, just visualize this result obtained through windowing. I'm sure it will give you a rough idea.
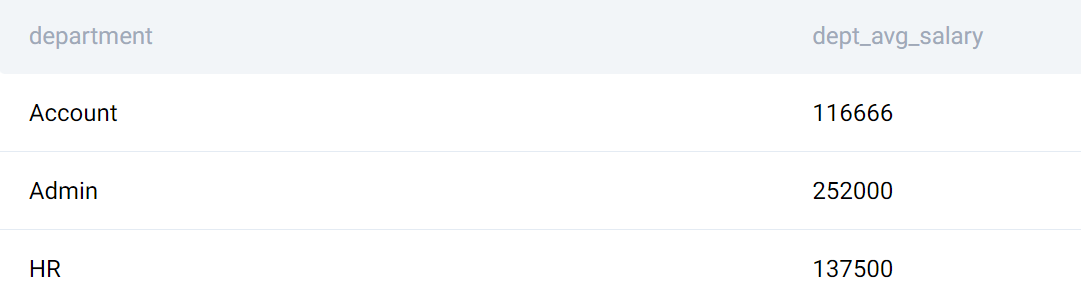
Notice how the salary for both departments has been aggregated (averaged) and displayed in the dept_avg_salary column, while the individual salaries remain intact in the salary column!
This is what I meant when I said “The former presents the aggregation against each row.”
Sometime in the future, when you learn more about SQL Window Functions, you may ask…
“Wait, wait, wait, what's the difference between GroupBy and Windowing.”
Let's make a distinction between GROUP BY and Windows Function before that day comes. Things are going to get a bit technical!
For each user-specified group, the GROUP BY function applies user-defined aggregations, which collapses multiple rows into a single one. This helps in summarizing the data, specifically!
Referencing the first example, the rows were grouped, however, the rows that lead to obtaining the dept_avg_salary weren't removed. In other words, the rows weren’t collapsed.
Window Functions uses pseudo-GroupBY (I’ll explain this) and aggregation to summarize data, however, it leaves the table as it is, i.e., it does not collapse the data into a single row per group. Instead, the aggregation output is added next to each row/ data point.
Before delving any further, I would like you to get to know the syntax used for Windowing. It’s pretty straightforward, making it easy to grasp!
Syntax:
Syntax Breakdown:
WINDOW_FUNC: The Aggregation you wish to apply to the data within the Window
OVER: ‘No Over clause, no Window’, meaning this clause is mandatory as it instantiates the Window!
PARTITION BY (optional): This is the same as GROUP BY, literally. It groups rows with similar values. Excluding it infers that the entire table should be considered as a single window/ group.
ORDER BY (optional): You know this one, it orders the data within individual windows.
Kindly hold your horses, this was just the introduction. Soon you’ll learn the intricacies that the above clauses hold!
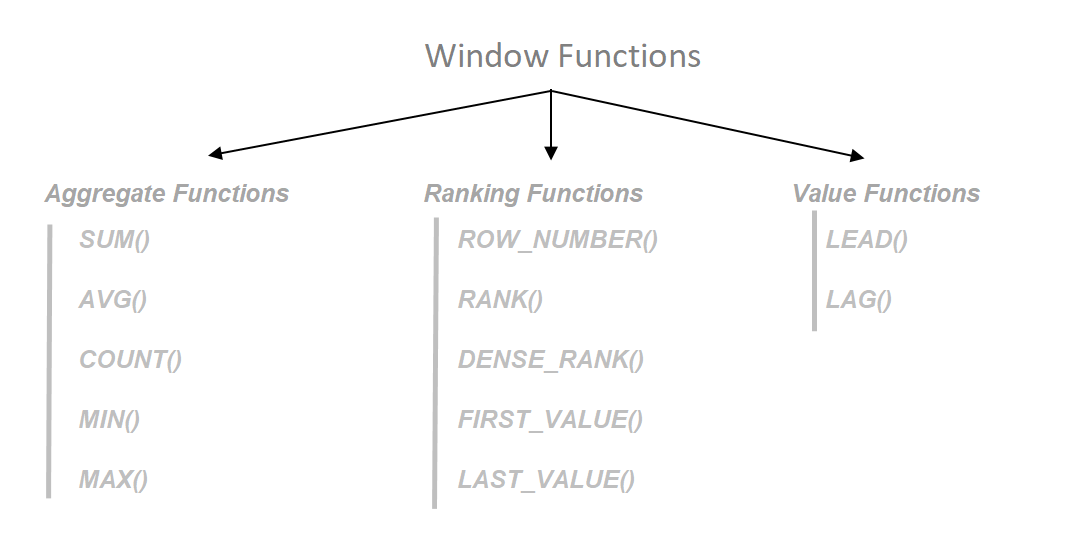
All the windowing functions are condensed into 3 types, each one having its own set of unique functions!
Aggregate Window Functions
Ranking Window Functions
Value Window Functions
You need to know the difference between the above three functions, their capabilities, and usage, which I shall cover all!
This article will contain the most prominent Window Functions, while the rarely to never-used functions will be excluded!
These functions simply aggregate data within the window and display the result across individual rows. The aggregate functions include SUM, AVG, COUNT, MIN, and MAX.
The SUM() function adds the values of all rows of a column within a user-defined window. Let’s learn by example.
Question
Suppose you have a table called sales that contains information about sales transactions, including the order_id, product_id, sales_date, and sales_amount. You want to calculate the total sales amount for each product, along with the running total sales amount for each product, sorted by sales date. Using SQL, write a query to achieve this.
Solution
Let's first understand what the running total is.
Suppose you have a list of daily sales for a product:
- Day 1: $100
- Day 2: $150
- Day 3: $50
The running total for this data would be calculated as follows:
- Day 1: $100
- Day 2: (including Day 1): $100 + $150 = $250
- Day 3: (including Day 1 and Day 2): $100 + $150 + $50 = $400
Solution Code
Code Breakdown
We use the SUM(sales_amount) function as a window function.
PARTITION BY product_id ensures that the sum is calculated separately for each product. It works exactly like the GROUP BY Clause.
ORDER BY sales_date is necessary since it sorts the rows by date in ascending order, i.e., from the 1st of the month unto the 30/31st of the month.
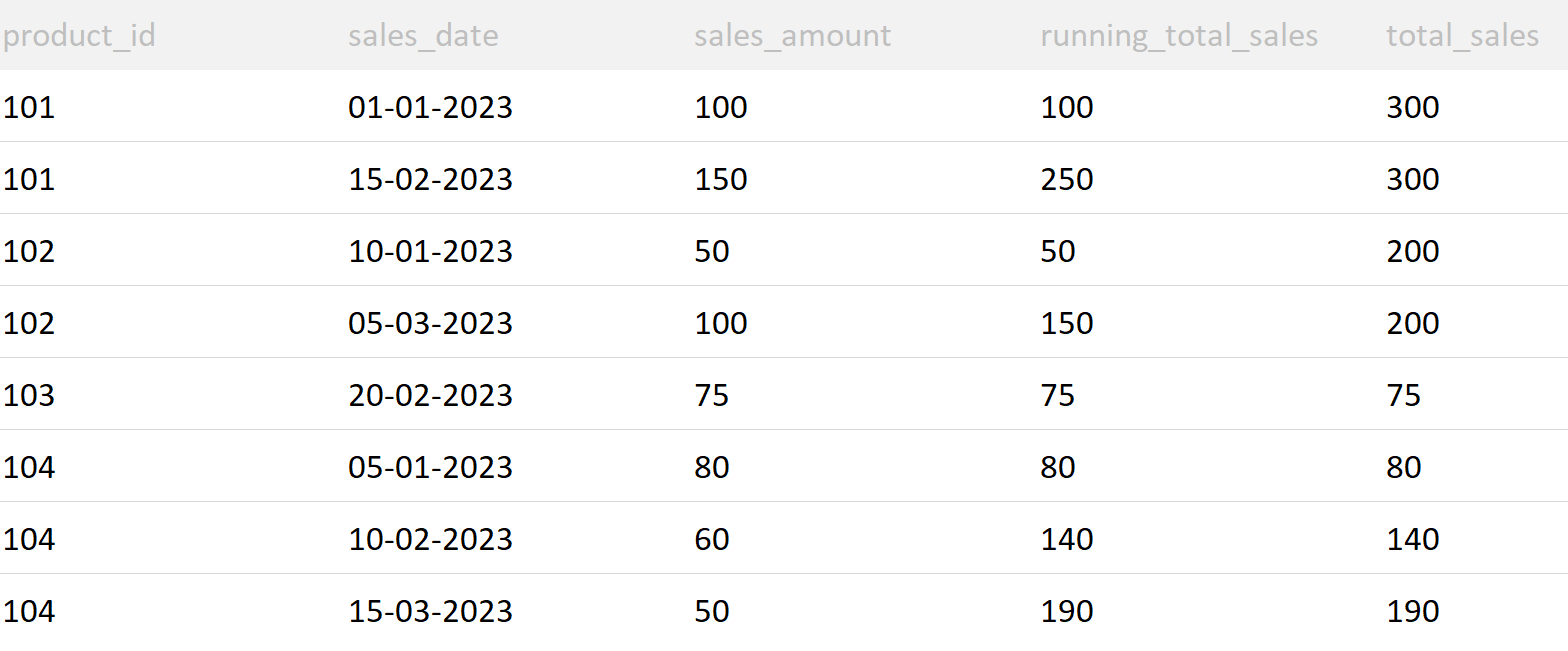
Result
The running total can only be calculated using the ORDER BY Clause, while total_sales cannot be calculated using it.
The AVG() function averages the values of all rows of a column within a user-defined window. Let’s learn by example.
Question
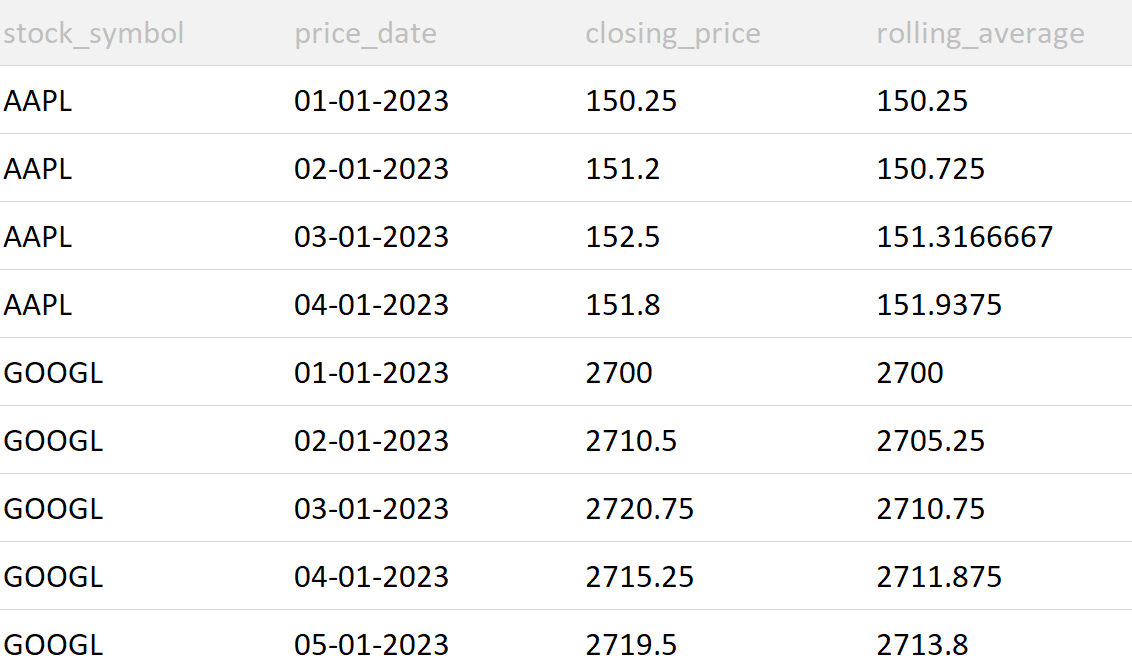
Write an SQL query to calculate the 30-day rolling average closing price for each stock symbol in the daily_stock_prices table. The result should include the stock symbol, price date, closing price, and the rolling average closing price.
Solution Code
Code Breakdown
AVG (closing_price): This part calculates the rolling average closing price using the AVG() function as a window function.
PARTITION BY stock_symbol: The PARTITION BY clause divides the data into partitions based on stock symbols, so the rolling average is calculated separately for each stock symbol.
ORDER BY price_date: The ORDER BY clause orders the data by price date to ensure it's processed in chronological order.
Result
One of the salient features of the rolling average is that it helps identify the outliers in the data. Suppose the closing_price on 06-01-2023 explodes, then the rolling_average on that day will also explode!
These Window functions are specially designed to rank the rows of a dataset. Any query that requires ranking based on sales, salary, purchases, etc. will utilize these functions.
You will grasp this topic once you go through a couple of examples.
This function assigns a unique number to each row according to how the data is sorted! In other words, it assigns a row number to each row.
Question
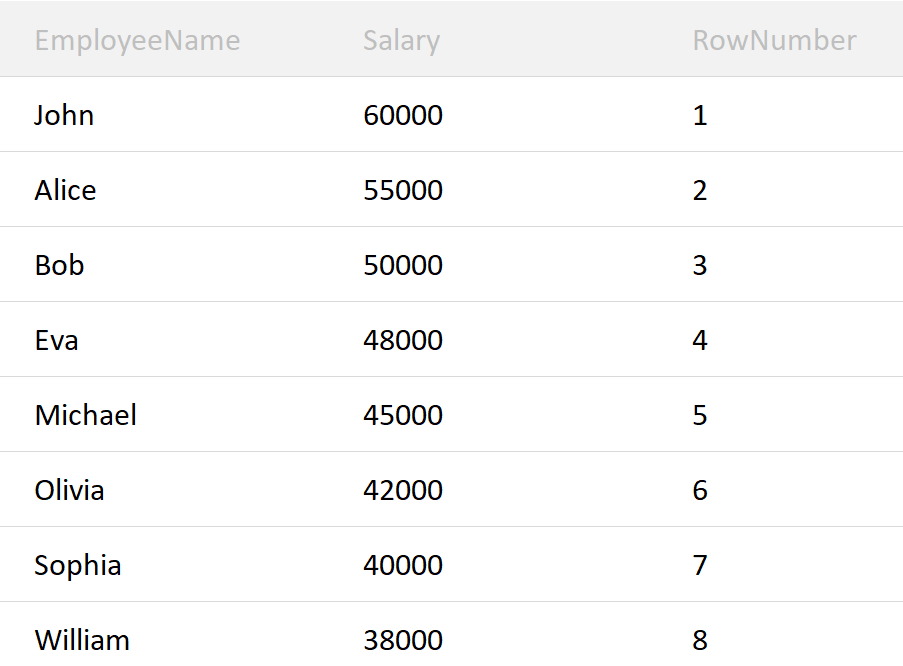
Suppose you have a table named Employees with the following columns: EmployeeID, EmployeeName, and Salary. You want to retrieve a list of employees with their names, salaries, and a unique row number assigned to each employee based on their salary, in descending order of salary.
Solution Code
Solution Breakdown
ROW_NUMBER(): This function returns a unique number to each row!
ORDER BY Salary DESC:
This is an essential clause since it defines how the rows are to be ordered!
DESC first sorts the data!
Subsequently, rows are numbered from top to bottom.
Results
This is the simplest way to rank your dataset based on the column you pass in the ORDER BY clause. However, further down you’ll learn that there is one functionality that it lacks!
Can you guess it?
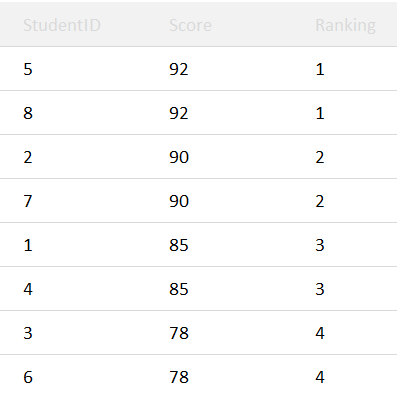
The RANK() function ranks all rows within a window. It assigns the same rank to rows with the same score/ value, i.e. rows that have tied. Furthermore, in case of ties, subsequent ranks are skipped (There is an example ahead clearly explaining this point).
Question
Consider a table named orders with the following columns:
order_id: The unique identifier for each order.
customer_id: The ID of the customer who placed the order.
order_date: The date when the order was placed.
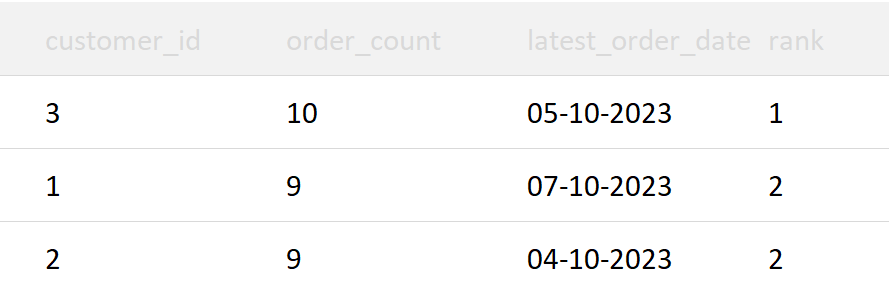
Write an SQL query to find the top 3 customers who have placed the most orders. If there are ties, assign the same rank to tied customers. Your query should return the customer_id, the count of orders they've placed, and their rank.
Solution Code
Solution Breakdown
The RANK() window function is used to assign a rank to each row. In this case, it is used to rank customers based on the number of orders they've placed, with the highest order count receiving a lower rank, i.e., 1st.
It also assigns the same rank to rows with the same order count. In other words, if multiple customers have the same number of orders, they will share the same rank.
Result
Visualize:
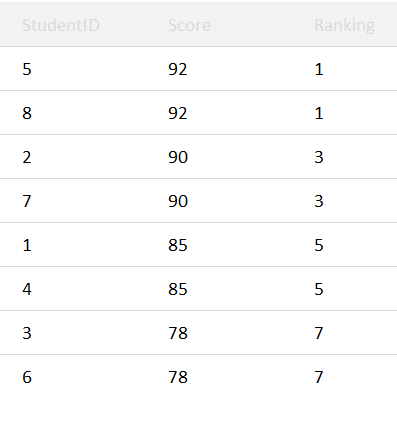
This function is completely similar to the RANK() function explained above. The only difference lies in the ranking procedure. In cases of ties, DENSE_RANK() doesn’t skip the following rank.
YES, That’s it!!
Referencing the above example, the 2nd rank will be assigned after the 1st. Thus, no ranks are skipped.
Here's a task…. Solve the question in RANK() using DENSE_RANK()…
HINT: just interchange RANK()
Result:
You may be thinking… “Sure sir, I’ve grasped the difference between the two rankings due to my competency… however, when is it to be used??”
In my opinion, it’s a good practice to use DENSE_RANK().
These functions return the values of the next/ preceding row while the current row is being processed. This may be the most important function, since generally while performing analysis we are required to calculate differences between the current row and the next/ preceding row.
Let's learn by example!
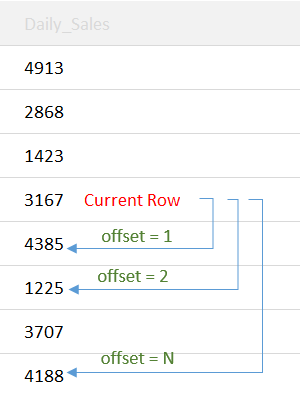
This function returns the value of the next row for the current row being processed!
Syntax
Offset: Consider it to be the index of the row starting from the row next to the current row. Default → 1.
Default: The last row returned by LEAD() is always NULL (you’ll see why!). The value passed into this will be the replacement for NULL.
Question
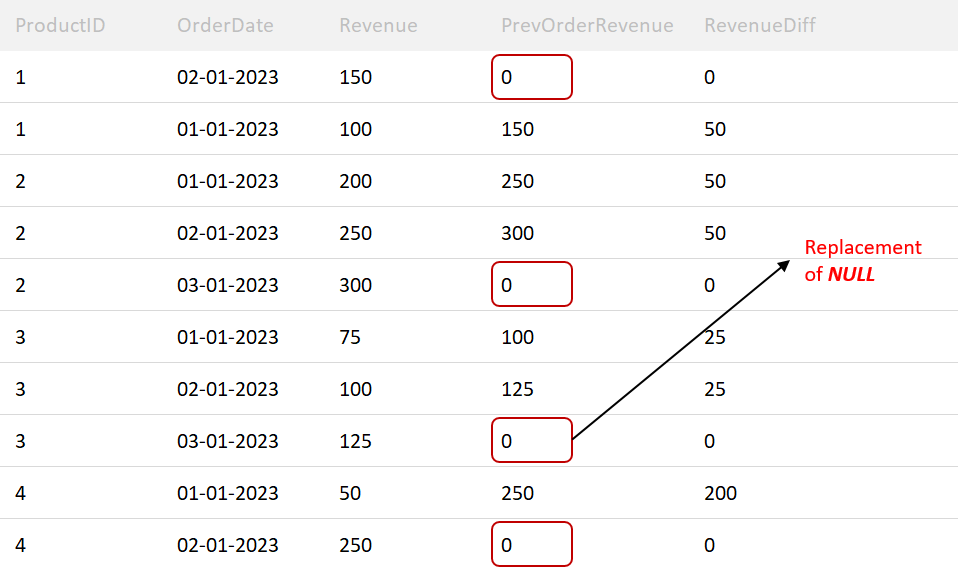
A table named Sales exists with the following columns: OrderDate, ProductID, and Revenue.
Create a query that returns the ProductID, OrderDate, and the revenue difference (RevenueDiff) between the current order and the next order for each product. If there is no next order for a product, treat the RevenueDiff as 0.
Solution
Solution Breakdown
LEAD (Revenue,1,0): Retrieves the value of the next order's revenue for the same product.
1 → Return the value of the next row.
0 → Replace NULL with 0.
LEAD(OrderDate,1,0): Retrieves the value of the next order date for the same product.
1 → Return the value of the next row.
0 → Replace NULL with 0.
PARTITION BY: Divides the data into partitions based on the ProductID.
ORDER BY: Orders the dates in ascending order. Remember what will happen if this clause is omitted.
Result
The reason why the last row of every product_id group is 0 is that if it takes the value of the next row (i.e. from the next group), the Window function gets violated (PARTITION BY product_id)
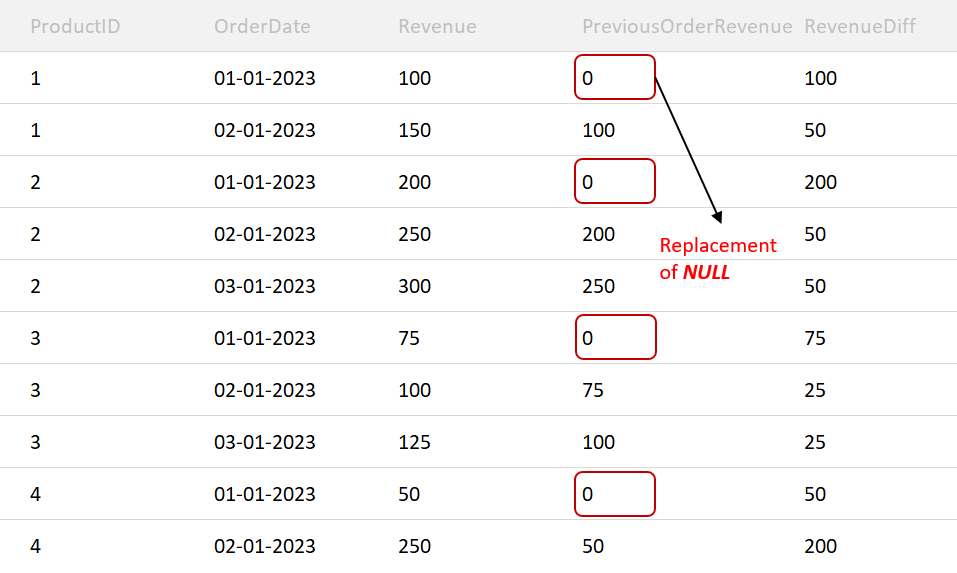
This function returns the value of the previous row for the current row being processed!
Syntax
Offset: In this case, the nth previous row will be chosen according to the specified offset.
A task again…. Solve the question in LEAD() using LAG()…
HINT: just interchange LAG()
In this example too, the 1st row is 0 since it’s a violation to take a value from the previous group!
By now, I hope you have gained valuable insights into SQL Window Functions. Also, I hope you comprehended the fundamentals of these functions, including Aggregate, Ranking, and Value Window Functions. Besides, keep in mind the key distinctions between Window Functions and GroupBy, the syntax for their implementation, and their practical use cases.
All in all, Windowing is a powerful tool for performing comparative analysis in SQL!!
HAPPY CODING!!